
پردازش اطلاعات با kafka
تاریخچه
آپاچی کافکا در ابتدا توسط لینکدین توسعه یافت و در اوایل سال ۲۰۱۱ بصورت نرمافزار متن باز درآمد. در نوامبر ۲۰۱۴ ، چندین مهندس که در لینکدین بر روی کافکا کار میکردند یک شرکت جدید به نام Confluentایجاد کرده و به صورت انحصاری بر روی توسعه کافکا کار کردند.
آپاچی کافکا چیست؟
آپاچی کافکا یک پلتفرم توزیعشده برای پردازش دادههای جریانی بوده و قادر به رسیدگی و پردازش چندین تریلیون رویداد به صورت همزمان است. کافکا در ابتدا به عنوان یک ابزار برای ارسال پیامهایی با تعداد بالا بکار برده میشد. کافکا از زمانایجاد و منبع باز شدن توسط لینکدین در سال ۲۰۱۱ ، به سرعت از ارسال پیام به یک پلتفرم پردازش توزیعی کامل تبدیل شده است.
آپاچی کافکا، به عنوان یک پلتفرم دادههای در جریان، دارای قابلیتهایی ازقبیل زمان پاسخ کوتاه، کارایی بالا و تحمل خطا بوده و قادر به پردازش جریانهایی سریع از رویدادها میباشد. کافکا، برای پشتیبانی از برنامههای کاربردی مشتری و اتصال سیستمهای پایین دست به دادههای زمان واقعی پاسخهای در حد میلی ثانیه فراهم میکند.
لایه ذخیرهسازی آن اساسا برای یک معماری کارگزار صف پیام (Message Broking) انبوه و مقیاس پذیر و برای تراکنشهای توزیع شده تولید شده است. تکنولوژی کافکا به طور مشخص برای پردازش جریان دادهها (Stream Processing) و کارگزار ارسال و دریافت پیام مورد استفاده قرار میگیرد که آن را بسیار با ارزش برای زیرساخت پردازش جریانی دادهها نموده است. علاوه براین، کافکا اتصال به سیستمهای خارجی (برای دادههای ورودی / خروجی) از طریق Kafka Connect و provides Kafka Streams فراهم میکند.
کافکا برای مواجهه با انبوهی از دادهها که بیوقفه در حال ارسال هستند و شما فرصت کافی برای پردازش و ذخیرهسازی آنها نداشته باشید تولید شده است.
کاربردهای کافکا
کافکا ™ برای استفاده در پروژههای زمان واقعی (real-time) به منظور فراهم آوردن خط لوله دادهها و جریان برنامهها استفاده میشود. کافکا به صورت افقی مقیاس پذیر، مقاوم در برابر خطا و بسیار سریع است و در تولیدات هزاران شرکت استفاده میشود.
دو مورد از اصلی ترین کاربردهای کافکا شامل موارد ذیل میشود:
1.ایجاد خطوط انتقال دادههای جریانی و بههنگام که دادهها را میان سیستمها و برنامهها بصورت قابل اطمینانی انتقال داده و رد و بدل میکند.
2.ایجاد برنامههای کاربردی برای دادههای جریانی و بههنگام که به موقع نسبت به جریانی از دادهها واکنش نشان داده و آنها را انتقال میدهد
ساختار و نحوه کار کافکا
قبل ازاینکه به ساختار کافکا بپردازیم ابتدا چند اصطلاح را توضیح میدهیم:
- کافکا به صورت خوشهای بر روی یک یا چند سرور کار میکند.
- کافکا جریان دادهها و رکوردها را در ساختارهایی به نام تاپیک( topics) ذخیره میکند.
- هر رکوردی دارای یک کلید، یک مقدار و یک برچسب زمانی میباشد تا بصورت مجزا از سایر رکوردها مشخص باشد.
کافکا دارای 4 رابط کاربری برای برنامه خود میباشد که هر کدام نقشی در مجموعه فعالیتهای کافکا دارند.این رابطها شامل:
- رابط تولیدکننده (Producer) که به یک برنامه اجازه میدهد رشتههایی از رکوردها را بر روی یک یا چند تاپیک کافکا منتشر کند.
- رابط مصرفکننده (Consumer) که به یک برنامه اجازه میدهد به یک یا چند تاپیک متصل شده و رکورهای موجود را پردازش کند.
- رابط جریانی (Streams) که به یک برنامه اجازه میدهد بصورت پردازشگر دادههای جریانی عمل کرده و دادههای ورودی موجود بر یک یا چند تاپیک را مصرف کرده و خروجی آن نیز تولید جریانی از دادهها بر روی تاپیکهای خروجی بوده و بصورت موثری جریانهای ورودی را به خروجی تبدیل میکند.
- رابط اتصالدهنده (Connector) که اجازه ساخت و اجرای تولیدکنندهها و مصرفکنندههایی با قابلیت استفاده مجدد را میدهد که تاپیکهای کافکا را به برنامهها و سیستمهای دادهای موجود متصل میکند. مثلا یک اتصالدهنده به یک پایگاه داده رابطهای میتواند هر نوع تغییری که بر روی یک جدول اعمال شده را ثبت و ضبط کند.
شکل زیر رابطهای کاربری و نحوه کار کافکا را بصورت شماتیک نشان میدهد.
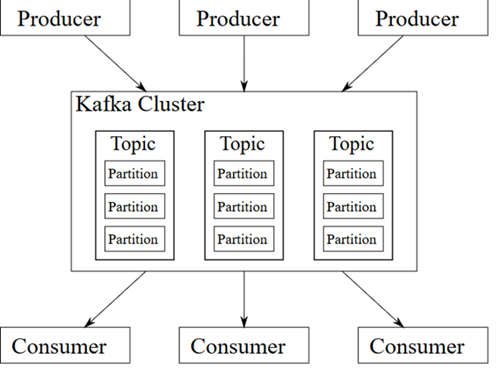
اولین قدم برای استفاده از این سیستم، ایجاد یک Topic میباشد. از این به بعد میتوان از طریق ارتباط TCP پیامهای جدید را جهت ذخیرهسازی در Topic جدید ارسال نمود. این کار به سادگی از طریق Clientهای پیادهسازی شده که به زبانها و برای پلتفرمهای مختلف طراحی شدهاند قابل انجام است. سپس این پیامها باید در جایی ذخیره گردد. کافکا این پیامها را در فایلهایی با نام Log ذخیرهسازی مینماید. دادههای جدید به انتهای فایلهای Log افزوده میگردند. کافکااین توانایی را دارد که پیامهای ارسالی را بر روی مجموعهای از سرورهای کافکا (Node) که با یکدیگر کلاستر(Cluster) شدهاند، ذخیرهسازی نماید. اگر به طور مثال تعداد n سرور کافکا در یک کلاستر وجود داشته باشند، دادههای مرتبط با هر پیام ارسالی پس از ذخیرهسازی بر روی سرور لیدر، بر روی تمامی سرورهای پشتیبانی نیز کپی خواهد گردید. بااین وصف، حتی اگر n-1 عدد از سرورها از سرویس خارج شوند، دادههای Topic مورد نظر کماکان در دسترس و قابل استفاده خواهند بود. از این رو تحمل پذیری در برابر خطا به خوبی در کافکا دیده شده است.
خواندن اطلاعات ذخیره شده بر روی کافکا (Kafka) نیز از طریق همان Clientهایی که برای ارسال پیامها مورد استفاده بودند قابل انجام است. کلاینت مصرفکننده پیام که به اصطلاح Consumer نامیده میشود، جهت خواندن پیامها باید خود را Subscribe یک Topic مشخص نماید. ازاین پس با اجرای متد Poll دادهها به سمت مصرفکننده سرازیر میشوند. در هنگام تعریف Topic جدید این امکان وجود دارد که دادههای مرتبط با آن در چند پارتیشن ذخیره شوند. پارتیشنها به سادگی جداسازی فیزیکی دادهها بر روی دیسک را انجام میدهند. در واقع کافکا تمامی پیامهای ارسالی به یک Topic را در تمامی پارتیشنها به همان ترتیبی که ارسال شدهاند به صورت توزیع شده ذخیره میکند.
دراین مدل ذخیرهسازی، هر پارتیشن بر روی یک سرور ذخیره شده و سایر سرورهای حاضر در Cluster نسخه پشتیبان آن پارتیشن را کپی خواهند کرد.این ویژگی کافکا به مصرفکننده پیام این امکان را میدهد که به صورت موازی اطلاعات را دریافت نماید. روش کار بهاین شکل است که به تعداد پارتیشنهای موجود یک Topic باید Consumer جدید تعریف شود و همگی آنها عضو یک گروه شوند. این کار به سادگی با انتخاب مشخصه group.id یکسان برای همه آنها قابل انجام است و پس از آن میتوان شروع به خواندن پیامها نمود. تمام هماهنگیهای مورد نیاز جهت تخصیص هر پارتیشن به یک مصرفکننده توسط کافکا (Kafka) انجام خواهد پذیرفت. در صورتی که تعداد مصرفکننده بیشتر از پارتیشنها باشد یکی از آنها در عمل استفاده نخواهد شد ولی اگر تعداد پارتیشنها بیشتر از تعداد مصرفکنندهها باشد به هر مصرفکننده بیش از یک پارتیشن جهت خواندن پیامها اختصاص داده خواهد شد. با تغییر در تعداد مصرفکنندهها، کافکا گروه مصرفکننده را دوباره تنظیم یا به اصطلاح Rebalance مینماید.
انواع کارگزارهای پیام کافکا
Message Brokerها به طور استاندارد به دو شکل Queuing و یا Topic (ویا Publish-Subscribe ) وجود دارند. در روش اول دادهها در یک صف قرار میگیرند و میتوان آنها را با ترتیب وارد شده به صف خواند. مزیت این روش این است که میتوان خواندن و پردازش را به صورت موازی انجام داد ولی با مصرف شدن هر پیام، به طور کامل از صف حذف میگردد. این ایراد در روش دوم به دلیل ارسال یک پیام به تمامی Subscriberها وجود ندارد ولی در عوض تقسیم بار کاری بی معنی میباشد. استفاده از کافکا مزیت هر دو روش را در اختیار میگذارد.
پارتیشنها پیامها را به ترتیب ورود ذخیره میکنند و مصرفکننده نیز به همان ترتیب پیام را دریافت میکند. با تخصیص هر مصرفکننده به یک پارتیشن، دریافت اطلاعات به صورت موازی انجام میگیرد. در عین حال محدودیتی در تعداد گروههای مصرفکننده یک Topicوجود ندارد و offset خوانده شده هر گروه جدا از گروههای دیگر نگهداری میگردد. Offset به نقطهای از پارتیشن که در فرمان Poll بعدی دادهها باید از آنجا خوانده شود اشاره دارد که میتواند به صورت خودکار توسط مصرفکننده بعد از خواندن دادهها کامیت شود و یا به صورت دستی توسط برنامه نویس بعد از پرداش اطلاعات کامیت گردد.
نحوه نگهداری اطلاعات پیکربندی کافکا
هر سرور کافکا دارای شناسهای میباشد که در کلاستر منحصر یه فرد است و به آن broker.id میگویند. هر Broker دارای Topicهای مربوط به خود است و هر Topic از مجموعهای از پارتیشنها تشکیل شده است. و در نهایت هر پارتیشن به ازای هر گروه مصرفکننده offset جداگانه نیاز خواهد داشت. این اطلاعات پیکربندی توسط Apache Zookeeper نگهداری میشود و کافکا برای اجرا نیاز بهاین سرویس دارد. Zookeeper اطلاعات مربوط به Topicهای یک Broker را در ساختار درختی ذخیره میکند.
این اطلاعات که در یک ساختار فایل سیستم مانند و به صورت Key,Value ذخیره میشوند در سرتاسر کلاستر در دسترس هستند. پیش از راهاندازی کافکا سرویس Zookeeper باید راهاندازی شده باشد و در پیکربندی کافکا نحوه اتصال به آن مشخص میگردد.
همینطور کافکا این ویژگی را دارد که جریان دادههای ورودی به یک Topic را پس از عبور دادن از یک پردازشکننده و تغییر حالت دادهها، در Topicهای جدید ذخیره نماید که این عمل به صورت بلادرنگ انجام میگیرد. به طور خلاصه کافکا ذخیرهسازی دادهها بر روی کلاستر، خواندن اطلاعات به صورت Publish-Subscribe و البته موازی جهت تقسیم بار کاری و پردازش همزمان جریان دادهها را در اختیار سیستمهایی میگذارد که دغدغه پردازش دادههای انبوه را دارند.